


- Collaborative Filtering
- Content-Based Recommendations
But we didn’t cover a couple of important aspects:
- How to combine Collaborative Filtering with Content-Based Models to improve quality?
- How to update Recommendation models on a fly?
Hybrid Recommendation Systems
Previously we’ve discussed how to build a Collaborative Filtering model, which is based purely on user events, and it works great for estimation of user interests and making personalized recommendations. It also detects relations between items and can help to cross-sell or make additional sales. But this model doesn’t know anything about the Item characteristics. What attributes are important and what is the business value of them.
On another hand, Content-Based Recommendations analyze all the Item attributes and perfectly detect Similar Items. Item Comparison Settings allow tuning of similarity models to reflect specific of your business domain- what attributes are important, how they need to be analyzed, etc. But these kinds of models don’t care about user interaction and interests.
Kea Labs is a Hybrid Recommendation System, which mixes advantages of both recommendation approaches, and achieves better relevance, and better quality in specific cases. Like: lack of events, the addition of new items, recommendations for anonymous users, etc.
Below we explain some examples when a Hybrid approach makes advantages.
“Long-tail” Recommendations
It’s very often when at the beginning you don’t have enough events to build recommendations, or the events matrix is too sparse and doesn’t cover most of the items. With a classical Collaborative Filtering, it results in a poor quality of recommendations.
A typical distribution of user interaction with items looks like this:
(the data is from MovieLens dataset. source:
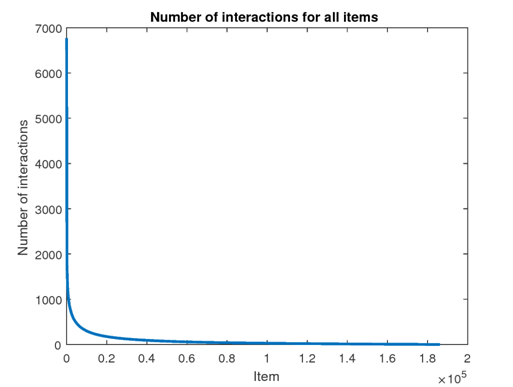
Only a low number of items have a big number of interactions when the rest items form a ‘long tail’.
It means, for most of the users the majority of recommended items are the same, and, of course – popular ones. How do we solve this in Kea Labs? The answer is below
Fast teaching of Recommendation Models
Kea Labs uses Similarity data to speed up the teaching of the event-based Recommendation algorithms, like Related items. When the user interacts with an item, a model considers not only the interacted item but also estimates how similar items can be interesting for the user.
For example, in a Bicycle store, a user has viewed a City Bicycle and a bell. Kea Labs also takes similar bicycles and similar bells and slightly connects them together. With the number of view events by other users, these relations are getting more visible and stable.
As a result, the algorithm can detect not only that specific items X and Y are close to each other, but the whole group of city bicycles is related with the bells. Or mountain bikes have stronger connections with aggressive off-road tires.
Recommendations for a New Item
The approach described above not only speeds up the education of recommendation systems but also solves a theoretical problem of recommendation engines. New, or rarely interacted items are not getting Recommended.
Naturally, if Kea Labs has already detected a connection between groups of Items, it can also find relations between the new members of the group.
So, when you add a new bell into your Bicycle store, it gets automatically recommended to the same kind of City Bicycles as other similar bells.
Once the user will interact with the new Item, the Recommendation model will be getting updated to give more accurate recommendations.
Personalization of Content-based Recommendations
As we can see, a Content-based approach improves the quality of Collaborative Filtering and event-based recommendations. But how does it work in another direction?
Kea Labs re-scores Content-Based Recommendations based on the detected user interests and previous interaction. The behavior is configurable in the recommendation model, but basically, you can:
- Prefer recommendations of items that the user hasn’t interacted with before.
- Or, an opposite – remind user about the previously viewed items
Realtime Updates of recommendation system
The recommendation model we’ve built in the previous article has been trained on historical data. This allowed us to detect relations between items and detect users with similar interests. The limitation of the current model – it can’t recommend data for the new user, because it doesn’t know anything about the user yet.
But Kea Labs is a realtime recommendation system and gets trained on a fly. The only thing you need to do – is just to send the user events as soon as they happen. Kea Labs updates user interests with every action, detects similar users, and makes personalized recommendations based on their interests.
Let’s have a look a practical example.
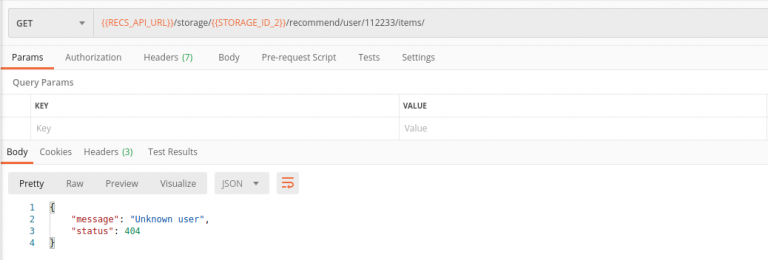
We want to get recommendations for the user 112233 from the MovieLens dataset. But this user doesn’t exist, and we see 404 error instead of recommendations.
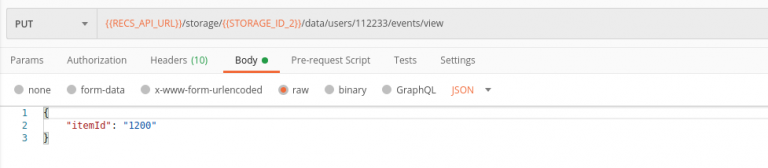
Ok, let’s send some events to Kea Lab. For example, user 112233 has seen the movie “Aliens (1986)” with id 1200.
Kea Labs immediately takes this information and compares user interests with other users. So, in about a second we can ask recommendations again. And now, Kea Labs suggests other movies, which have been viewed by there users who watched the movie 1200.
Note- the weight of recommendations is relatively low, which means having one event for a user is not enough to be confident in recommendations.
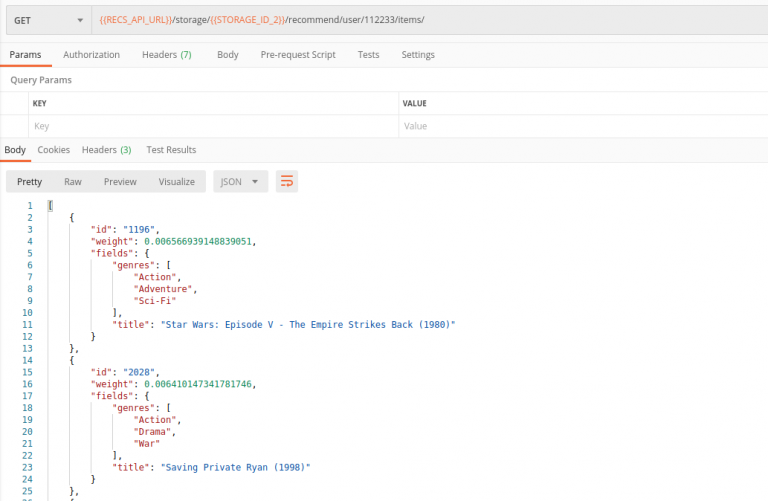
As you may see, Kea Labs trains recommendation models in near-realtime and adjusts personalized recommendations with every user action.
It’s very easy to use and suits any domain- e-commerce, news, articles, movies, music, or anything else.






