


Defining Item Similarity Model
In Kea Labs Dashboard you can configure multiple Similarity models and use them for recommendations. Some of Content-based algorithms, like SImilar Items are made purely on these models, when others, like Related Items are mixing this information with the user events.
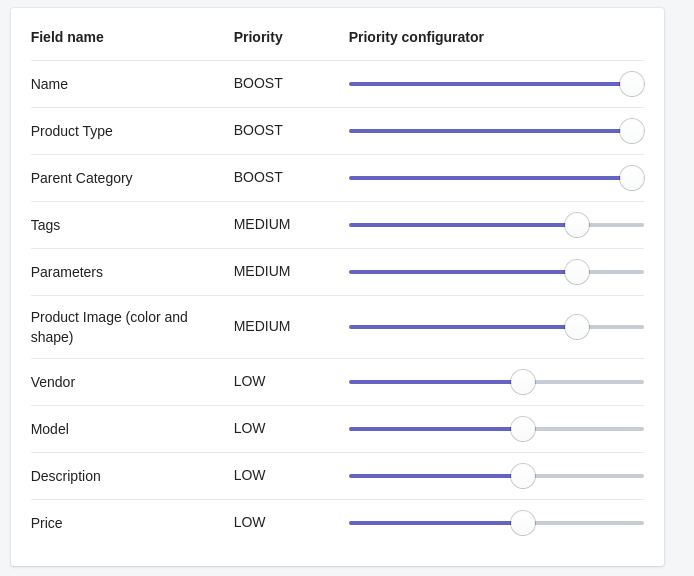
Each of the Similarity models defines the importance for item Attributes, and rules for analysis.
Comparing Item Attributes
Naturally, Item attributes have different data types and need to be compared differently. To support this in Kea Labs we have such comparison rules for attributes:
- String – linguistic analysis of string, stemming and tokenization. It works well for most of the strings
- Text – similar to String, but is designed for large texts, like product descriptions, or text of the article. This comparator type analyses the whole text, extracts keywords and general meaning. Later this output is used for comparison, instead of the full text.
- Keyword – value is compared ‘as is’, without any processing, so it’s considered as a keyword. It can be used for attributes like Brand. However, we recommend String comparator
- Number – basic numerical comparison. What value is lower or bigger.
- Number Segment – performs segmentation of this attribute across all items, and splits values into the segments. This comparator is good for such attributes, like prices.
- Color – compares color from the Human perspective – what colors are visually close to each other. It works especially well with Kea Labs image processing, which automatically detects color information from photos. Extra configuration is required, we’ll cover it in other articles. Comparator also supports attributes with hex color values. This comparator is useful for fashion, design, or any visual recommendations.
Defining priority for Attributes
Similar to comparatos selection, you can specify priorities for Attributes.
Priorities are represented as multipliers on scale from 0.1 to 10. Default value is 1.0, which means- don’t modify weights produced by the comparator.
If you want to boost the priority of some attribute, i.e. Brand – simply make it bigger than 1.0 – as the result, weight will be multiplied.
Sometimes, negative priorities are useful, for example – you want to force recommendations from another Brand, to show similar items, but produced by another manufacturer. To do this- just make the priority between 0.1 and 1.0. Where 0.1 means that weights will be decreased 10 times.
Building Content-based Recommendation System in Practice
Ok, let’s try everything on practice. Our goal is to set up a Similarity Model and generate pure Content-based Recommendations for Similar Items.
In this example we’ll be using a dataset prepared by our Analytics team. This dataset contains data tracked in the electronics tools stores together with the Product Attributes. This is a very complicated area for recommendations, as products in different categories have different important attributes and recommendations need to handle them properly.
At this point we’ll be using only Items data to show how Similarity detection works. We’ ll add events data in the next article to show how events improve content based recommendations.
Let’s start from defining the Similarity Model. Open Kea Labs Dashboard and change settings for default Similarity Model.
For example, let’s take such settings:
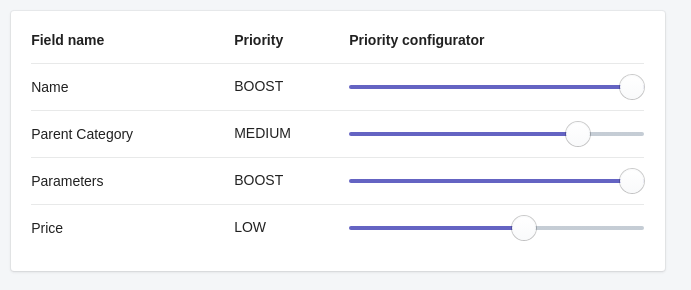
Once a Similarity Model is defined, we can start populating the data.
The file was extracted from Shopify store and follows this specification: https://help.shopify.com/en/manual/products/import-export/using-csv#product-csv-file-format
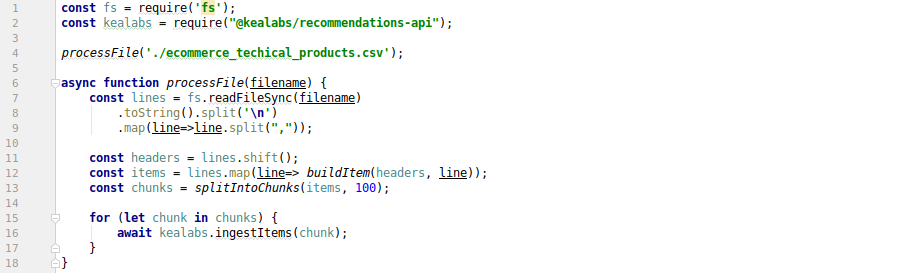
Let’s parse the file and upload product information via bulk API requests. We’ll be using Node.js here, but similar techniques are applicable for any other language.
Once data is fully uploaded, Kea Labs starts items analysis and re-generates recommendations for all of defined Similarity Models.
In the first run this may take a couple of minutes to complete.
Getting Recommendations for Similar Items
Once Recommendation Models are trained, we can start getting the recommendations for Items.
Let’s get prepared to zombie apocalypses
and take some Diesel Generator and a chainsaw.
We’d like to take similar Diesel Generator with Auto Voltage Regulator and Protection class IP23.
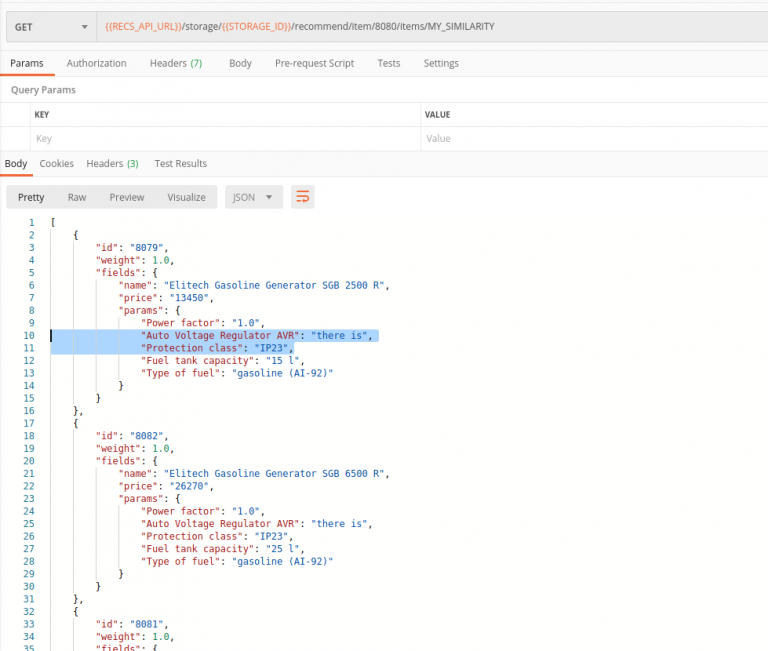
Let’s find a similar Chainsaw, with a power close to 3.2kW
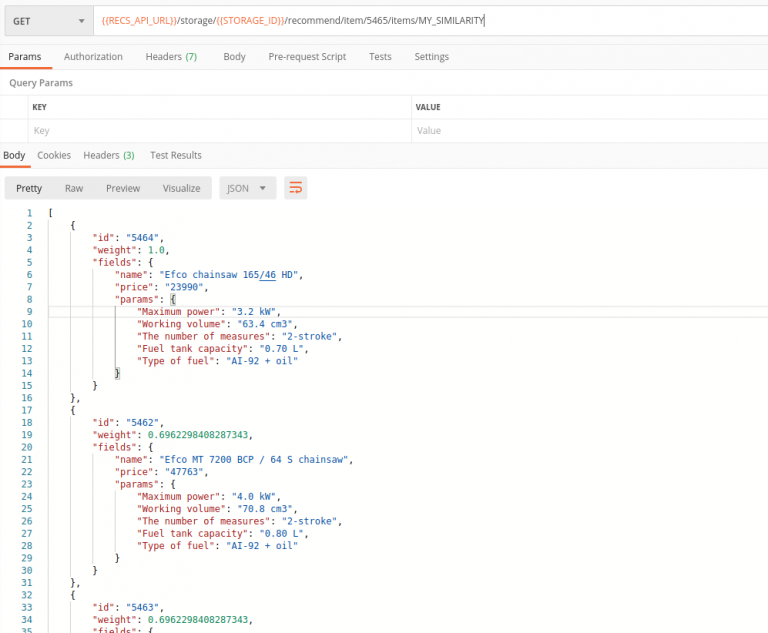
As you may see – userId is present in the request, but it’s not affecting recommendations since we don’t have any events loaded into the Recommendations System.
In one of the next articles we’ll tell you how to make a Hybrid Recommendation System, which will combine advantages of the content-based recommendations, and a Personalised Recommendations from the previous article.






