


- Introduction to Recommendations API
- Building Recommender System with Personalisation
- Building Content-Based Recommender System
- Hybrid Recommendation Systems
- Realtime updates of Recommendation System
- How to improve Product Recommendations
Building Recommender System
In this article we will build a Collaborative Filtering recommendation system that generates personalized recommendations for a user. This model will be built on the historically tracked data, it won’t support data updates, and won’t care about the content details. All these areas are covered in further articles. However, this model suits well for personalized recommendations for existing users, and recommendations of related items.
Datasets for Recommender System
There’re many public datasets available for various data science tasks. Good list of datasets for recommendation is available in the University of San Diego website: https://cseweb.ucsd.edu/~jmcauley/datasets.html
Another good list of open-source dataset is here: https://analyticsindiamag.com/10-open-source-datasets-one-must-know-to-build-recommender-systems/
Let’s take the famous MovieLens dataset by Group Lens, which is often used for experimenting with recommendation engines. It contains ratings and tags applied to movies by users. Dataset is available in different sizes – from 100K raings, to 25M. We’ll take the set with 1 milling ratings, as it’s convenient to use for development purposes.
Dataset is available here: https://grouplens.org/datasets/movielens/
Uploading data into Recommendation System
First of all, you need to upload data to Kea Labs Recommendations API.
There’re at least 3 ways to upload data to Kea Labs, you can read about them in documentation.
These methods are:
- general API requests (like add item, add rating),
- bulk API requests (which batches operations into 1 request)
- ingest methods, which supports multipart requests with a file uploading and configuration.
movies.csv – with movies data, which contains fields: movieId,title,genres
like:
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
2,Jumanji (1995),Adventure|Children|Fantasy
3,Grumpier Old Men (1995),Comedy|Romance
ratings.csv with ratings that users gave to movies.
Fields are: userId,movieId,rating,timestamp
1,1,4.0,964982703
1,3,4.0,964981247
1,6,4.0,964982224
1,47,5.0,964983815
As you can see, some of the movies have multiple genres associated. The list is separated by | symbol. Interest methods support this, but it’s better to have files in a cleaner format.
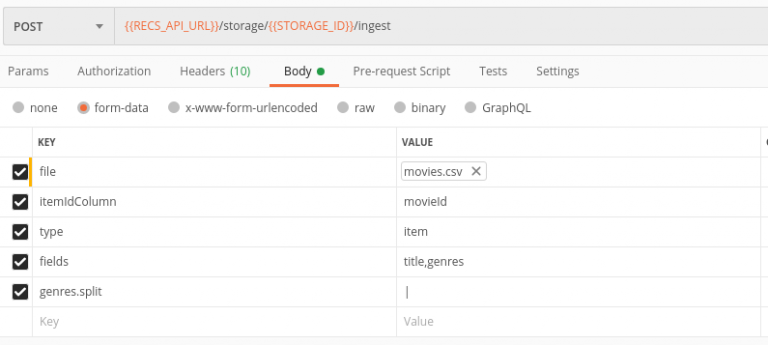
Let’s upload file movies.csv into url:
/{$storageId}/ingest?type=item&fields=title,genres&itemIdColumn=movieId&genres.split=|
In this url we specify some parameters:
- type=item – we upload items data
- fields=title,genres – specifies additional data fields
- itemIdColumn=movieId – we need to specify name of id column, since the file has custom column names
- genres.split=| – split genres column by | and upload them as an array
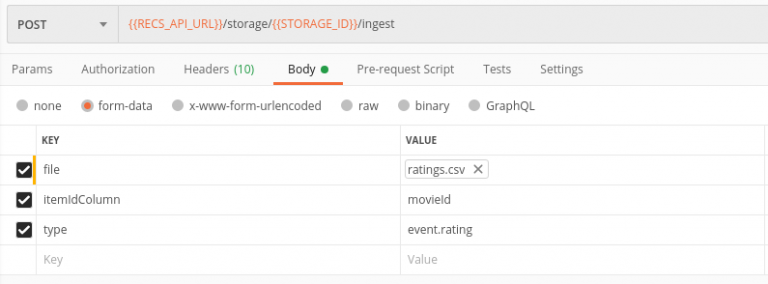
Let’s upload ratings data into url:
/{$storageId}/ingest?type=event.rating&itemIdColumn=movieId
- type=event.rating – we upload rating events data
- itemIdColumn=movieId – again we need to specify name of id column, since the file has custom column names. The rest fields are the same as ingest command expect – rating, userId and timestamp
Getting personalized Recommendations for User
Once the data uploading completed, Kea Labs needs to fully regenerate the recommendation model. It may take a couple of minutes. But note- this is happening only on initial uploading and on ingest command. Other data updates on a fly and are getting applied on top of generated models.
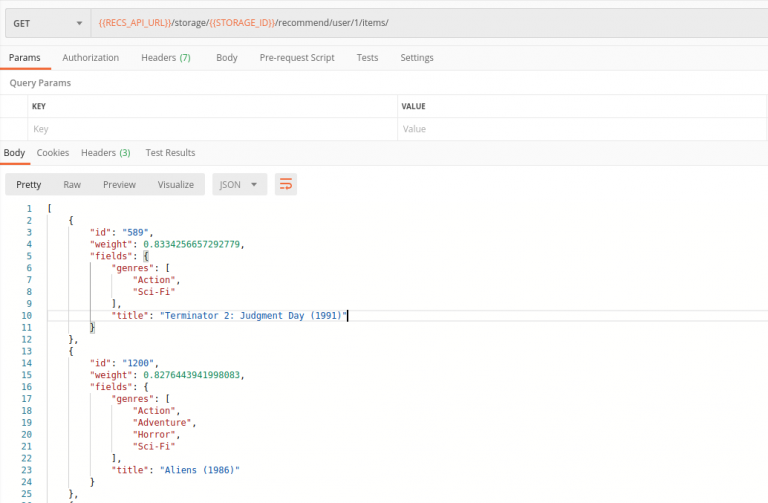
Let’s get a personalized recommendation for the user with id=1.
It’s simple as sending GET request to /storage/{{STORAGE_ID}}/recommend/user/1/items/
It looks like this user might be interested in classic Action/Sci-Fi movies, like legendary Aliens, or Terminator 2.
Let’s check why Terminator 2 got recommended to user #1. For this, we can send a request to the /explain method. It evaluates user interactions and explains why a given item has been recommended.
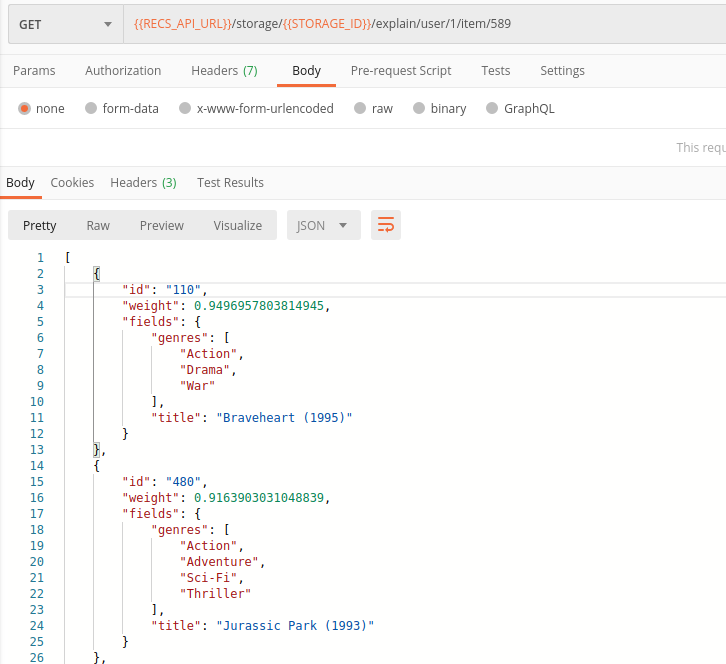
Nice! Based on the user preferences we can see that recommended classical Action movies, like Terminator 2 are interested to user.
Further reading
In this article we’ve built a simple, but fully operating Recommender System for personalized user recommendations.
In further articles we’ll cover how to make this model updating, how to recommend items for anonymous or new users.
You can subscribe to our updates and you won’t miss the next practical tips.






